Statistics and Research Design Review
Example Study
We are conducting an experiment studying the effect of sleep on memory. Participants are randomly assigned to one of two groups: 8 hours of sleep (normal sleep) and 4 hours of sleep (shortened sleep). In the morning, participants are asked to complete an n-back task to test their working memory. In this task, participants are shown a sequence of letters one at a time. For each letter currently on the screen, they must determine whether it matches a letter presented a certain distance before it. The task has two difficulty levels in two blocks:
- One-back (easy): participants perform a one-back task, where they must determine whether the current letter matches the one presented immediately before it.
- Three-back (hard): participants perform a three-back task, where they must determine whether the current letter matches the one presented three screens before it.
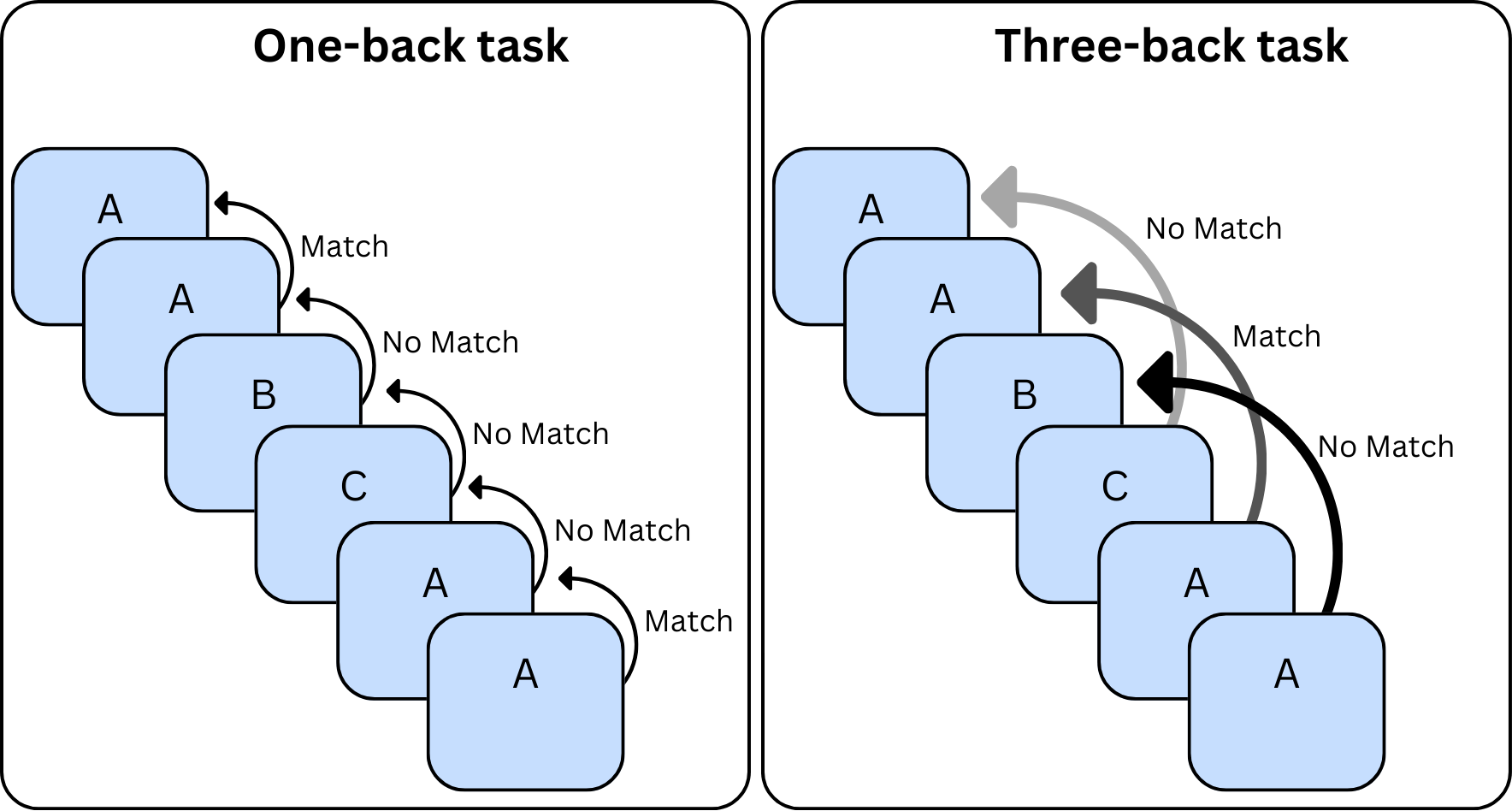
Their accuracy and reaction time for each response is recorded. We hypothesize that, for all participants, reaction times will be longer for the three-back task compared to the one-back task, and that accuracy will be lower for the three-back task compared to the one-back task. We also hypothesize that participants in the shortened sleep group will have worse performance (longer reaction times and lower accuracy) compared to the normal sleep group.
Variables
Independent Variable: An independent variable is the variable that the researcher manipulates or changes in an experiment to observe its effect on another variable. It is called "independent" because it is presumed to be independent of other variables in the study. The independent variable represents the cause or treatment, and its different levels or conditions are compared to see how they impact the outcome.
- Example: In our experiment studying the effect of sleep on memory, the amount of sleep participants receive (4 hours vs. 8 hours) is the first independent variable. This IV has two levels (normal sleep = 8 hours; shortened sleep = 4 hours). The difficulty level (easy vs. hard) of the n-back task is the second independent variable. This IV also has two levels (easy = 1-back; hard = 3-back).
Dependent Variable: A dependent variable is the variable being measured or observed in an experiment. It is called "dependent" because its value is thought to depend on changes in the independent variable(s). The dependent variable represents the outcome or effect, and its variation reflects the impact of the independent variable(s).
- Example: In our experiment studying the effect of sleep on memory, the reaction times and accuracy on the n-back working memory task are the two dependent variables, as these are expected to change based on the amount of sleep (IV #1) and difficulty level of the n-back task (IV #2).
Types of Data
Categorical: Categorical data consists of variables that represent distinct categories or groups. These categories are typically qualitative and do not have a natural order (though some categorical variables can be ordinal, like ranking). Categorical data is often represented with labels or names and is analyzed with different statistical techniques than continuous data.
- Example: In our experiment studying the effect of sleep on memory, the difficulty level (easy vs. hard) is a categorical variable. Accuracy (correct vs. incorrect) is also a categorical variable.
Ordinal: Ordinal data is a type of categorical data where the values have a meaningful order or ranking, but the intervals between the values are not necessarily uniform or known. This means that while you can determine which values are greater or less than others, you cannot quantify the exact differences between them.
- Example: In our experiment studying the effect of sleep on memory, the amount of sleep participants receive (4 hours vs. 8 hours) is an ordinal variable, because we are assuming that 8 hours is better (more normal) than 4 hours of sleep.
Continuous Data: Continuous data consists of variables that have an infinite number of possible values within a given range. This type of data is quantitative, meaning it represents measurements or quantities, and can take on any value along a continuum. Continuous data is often analyzed using means, standard deviations, and other measures that assume a continuous scale.
- Example: In our experiment studying the effect of sleep on memory, the reaction times on a memory task is a continuous variable.
Study Designs
Within Subjects:
In a within-subjects design, each participant is exposed to all levels of the independent variable. This means that each participant acts as their own control, experiencing each condition or treatment in the experiment. Because each participant is tested under multiple conditions, within-subjects designs help reduce variability due to individual differences, often making the experiment more statistically powerful.
- Example: In our experiment studying the effect of sleep on memory, the easy vs. hard memory trials are a within-subjects variable.
- To make our experiment a true within-subjects design, we would need to have every participant complete both versions of the n-back after a night of normal sleep AND after a night of shortened sleep (e.g., make the between-subjects variable of group a within-subjects variable).
Advantages:
- Reduced variability due to individual differences.
- Often requires fewer participants.
Disadvantages:
- Potential for order effects (e.g., practice or fatigue).
- May require counterbalancing to minimize these effects.
Between Subjects:
In a between-subjects design, different groups of participants are exposed to different levels of the independent variable. Each participant experiences only one condition, so comparisons are made between groups rather than within the same individuals.
- Example: In our experiment studying the effect of sleep on memory, the amount of sleep participants receive (e.g., 4 hours vs. 8 hours) is a between-subjects variable.
- To make our experiment a true between-subjects design, we would need to have four groups of participants (e.g., make the within-subjects variable of condition a between-subjects variable):
- Normal Sleep + Easy N-back
- Normal Sleep + Hard N-back
- Shortened Sleep + Easy N-back
- Shortened Sleep + Hard N-back
- To make our experiment a true between-subjects design, we would need to have four groups of participants (e.g., make the within-subjects variable of condition a between-subjects variable):
Advantages:
- No risk of carryover effects between conditions.
- Easier to design and implement if conditions are complex or likely to influence each other.
Disadvantages:
- More participants are typically needed.
- Higher variability due to individual differences between groups.
Mixed Design:
A mixed design (or mixed-factorial design) combines elements of both within-subjects and between-subjects designs. In a mixed design, there is at least one within-subjects factor (where the same participants experience multiple levels of a variable) and at least one between-subjects factor (where different participants are in different groups).
- Example: In our experiment studying the effect of sleep on memory, the overall study is a mixed design because it has both between-subjects variables (amount of sleep) and within-subjects variables (easy vs. hard memory blocks).
Advantages:
- Balances the benefits of both designs: reduces individual variability for the within-subjects factors and avoids carryover effects for the between-subjects factors.
- Can reveal complex interactions between factors.
Disadvantages:
- More complex to analyze and interpret.
- Can be challenging to design due to the need to control for multiple types of effects.
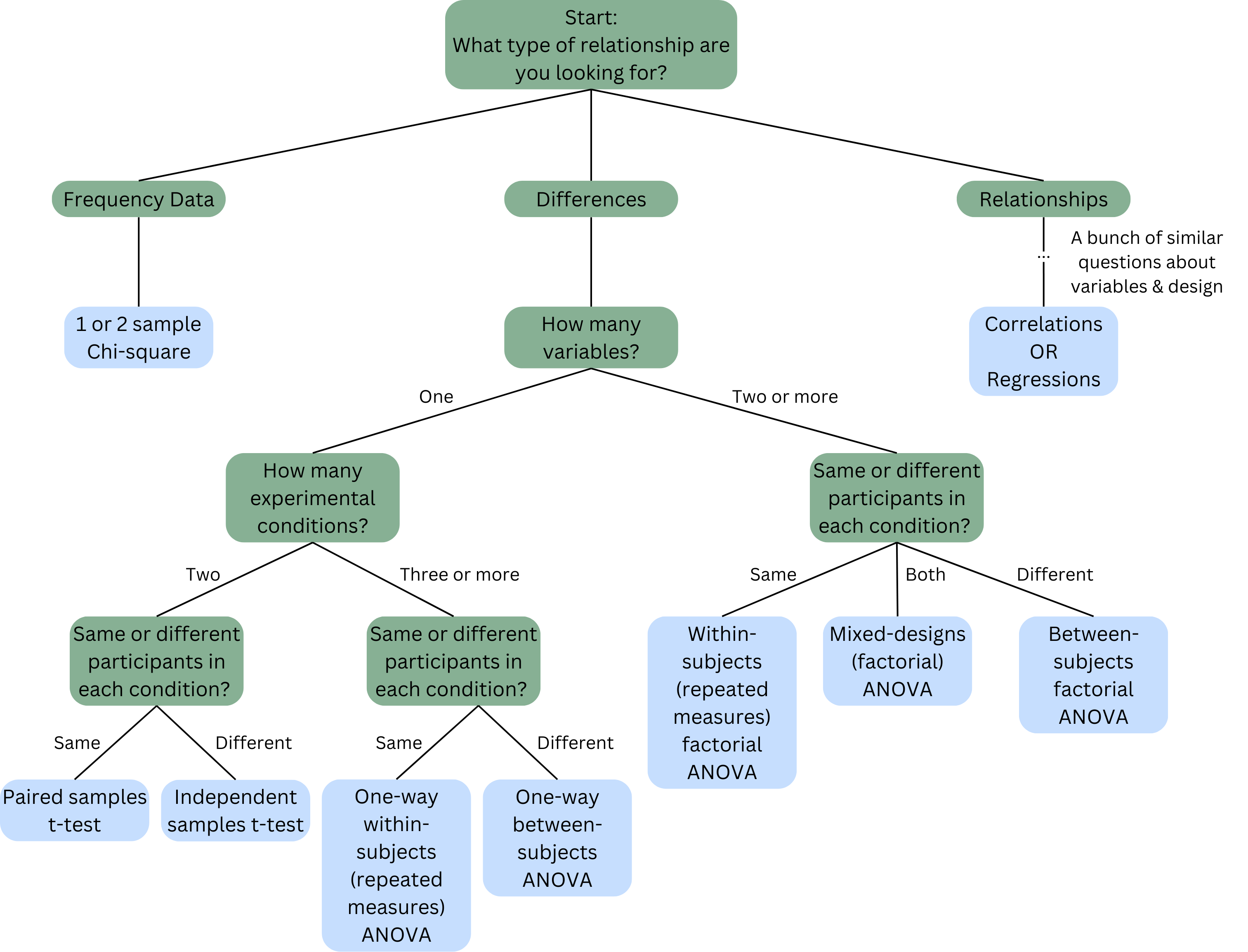
Mixed Design ANOVA:
A mixed-design ANOVA (also called a split-plot ANOVA or mixed-factorial ANOVA) is a statistical test used to analyze data from experiments that involve both within-subjects and between-subjects factors. It allows researchers to test for main effects and interactions across both types of factors, making it a powerful tool for experiments that have a complex design.
Purpose of Mixed-Design ANOVA
A mixed-design ANOVA is particularly useful in psychology and behavioral research because it:
- Accounts for individual differences in within-subjects factors by comparing participants against themselves, which reduces error variance.
- Examines group differences in between-subjects factors, allowing for comparisons between different types of participants or groups.
- Tests for interactions between within- and between-subjects factors, which can reveal complex patterns in how different conditions affect behavior or responses.
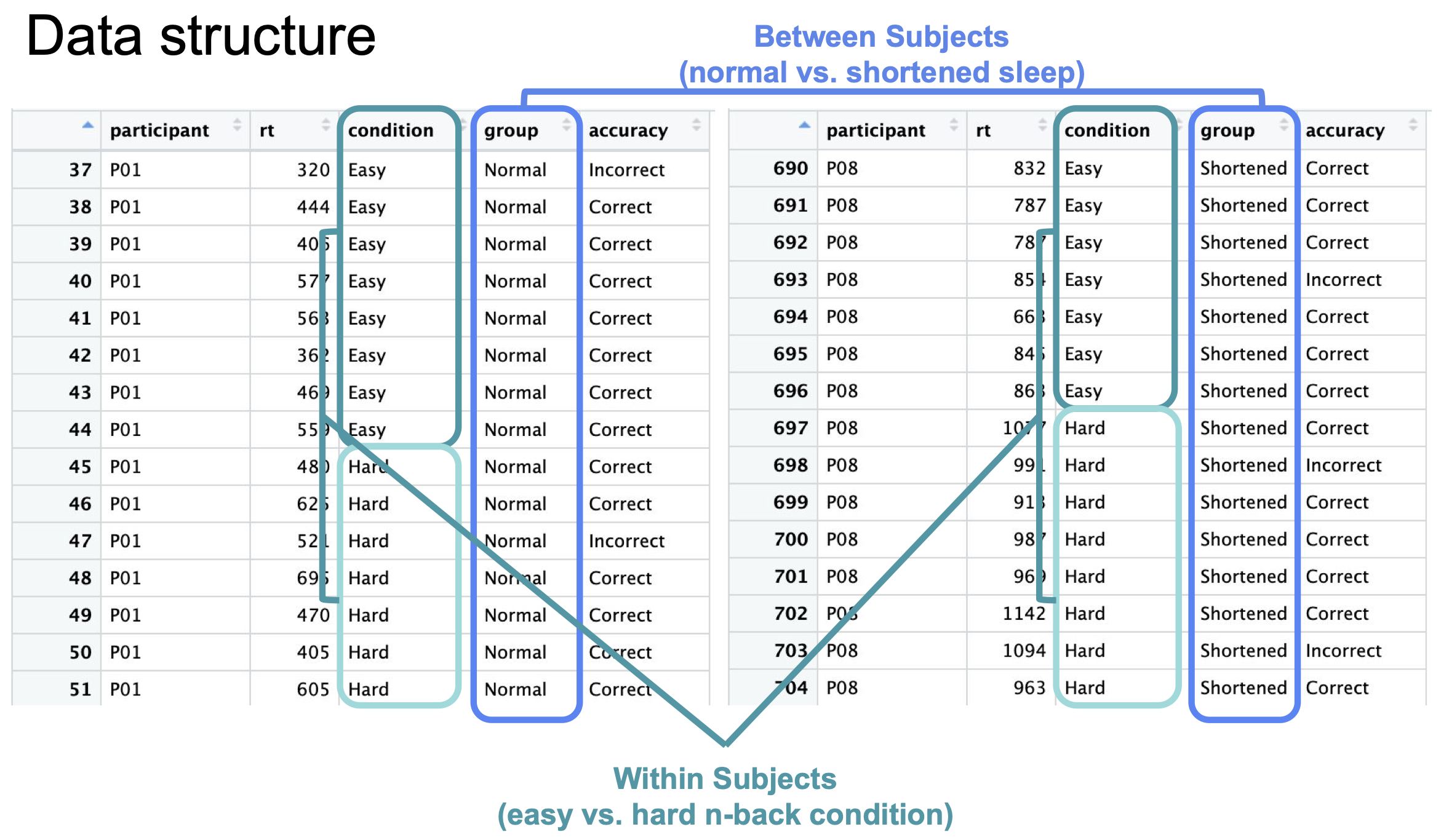
Long Data Format
Long format data is a way of organizing data where each row represents a single observation or measurement for a particular subject (or unit of analysis) at a specific time point or condition.
In long format, you have:
- A unique row for each combination of subject (or unit) and time point/condition.
- Columns for identifiers like subject ID and time/condition/block (these may repeat for each row for a given participant).
- Columns for variables being measured, where each row contains a single observation of the measured variables.
This structure is particularly useful for repeated measures data (e.g., multiple observations for the same subject) and panel data because it allows for easy handling in statistical analysis, especially for models like mixed-effects models that can account for within-subject variability.
Key Terms and Concepts
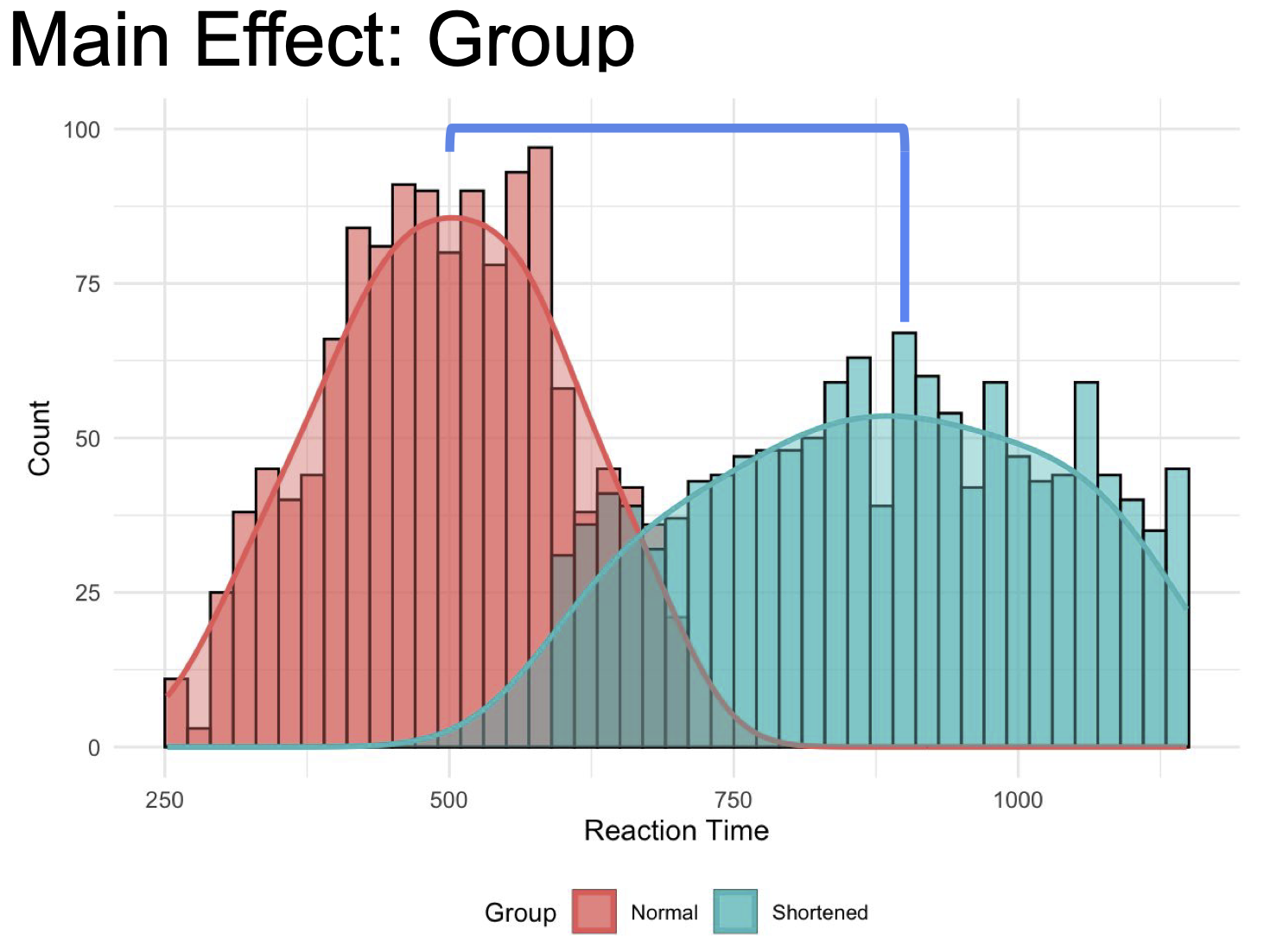
Main Effects: The impact of each independent variable (factor) on the dependent variable, independently of other factors.
- Example: The main effect of sleep group (normal vs. shortened) on reaction time might reveal that reaction times are overall longer following a shortened night of sleep compared to a normal night of sleep.
- Example: The main effect of task condition (easy vs. hard) on reaction time might reveal that reaction times are overall longer for the hard version (three-back) of the task compared to the easy version (one-back) of the task.
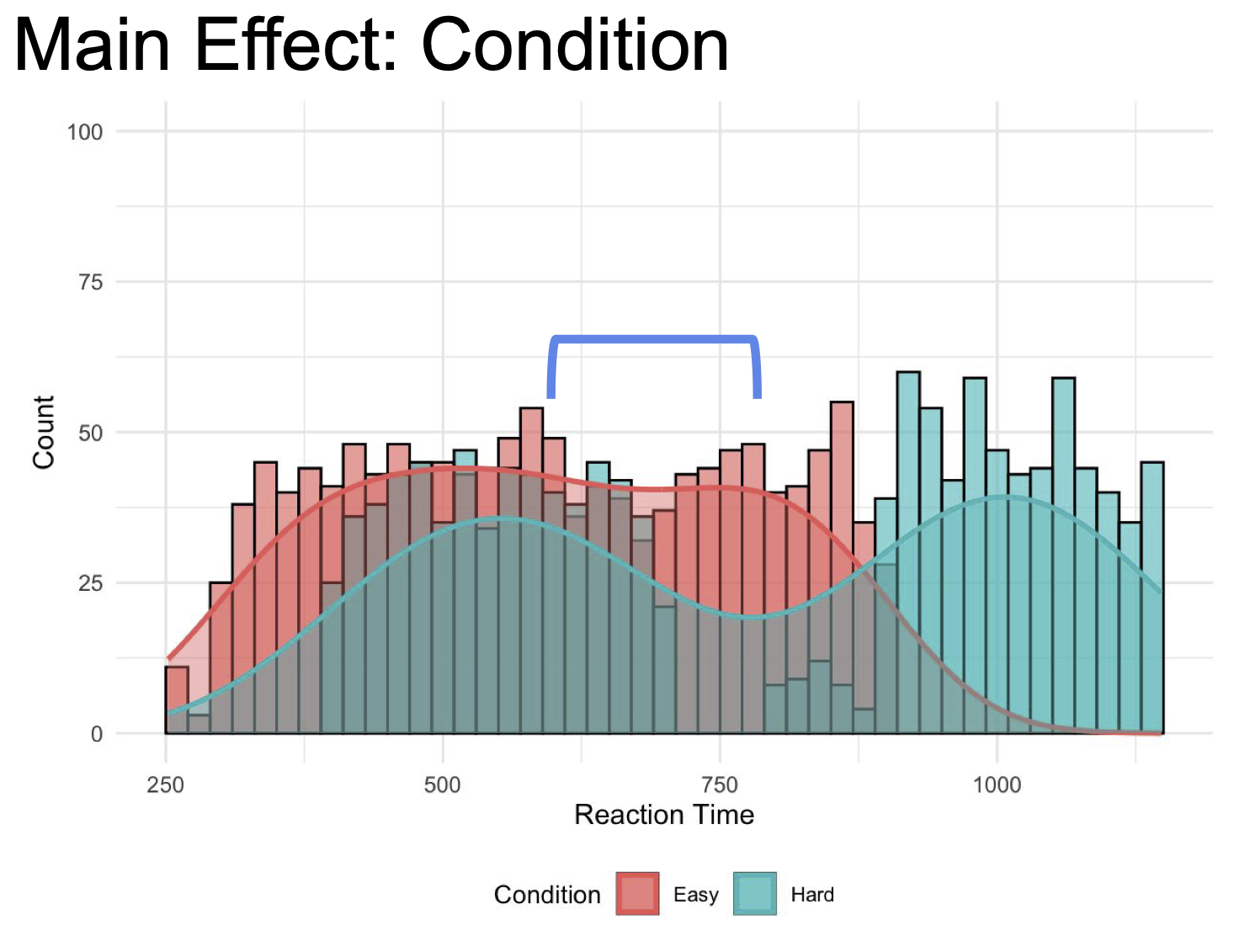
Interaction Effects: When the effect of one independent variable on the dependent variable depends on the level of another independent variable.
- Example: An interaction effect might reveal that the difference in reaction times to the hard vs. easy condition is much larger following a shortened night of sleep compared to a normal night of sleep.
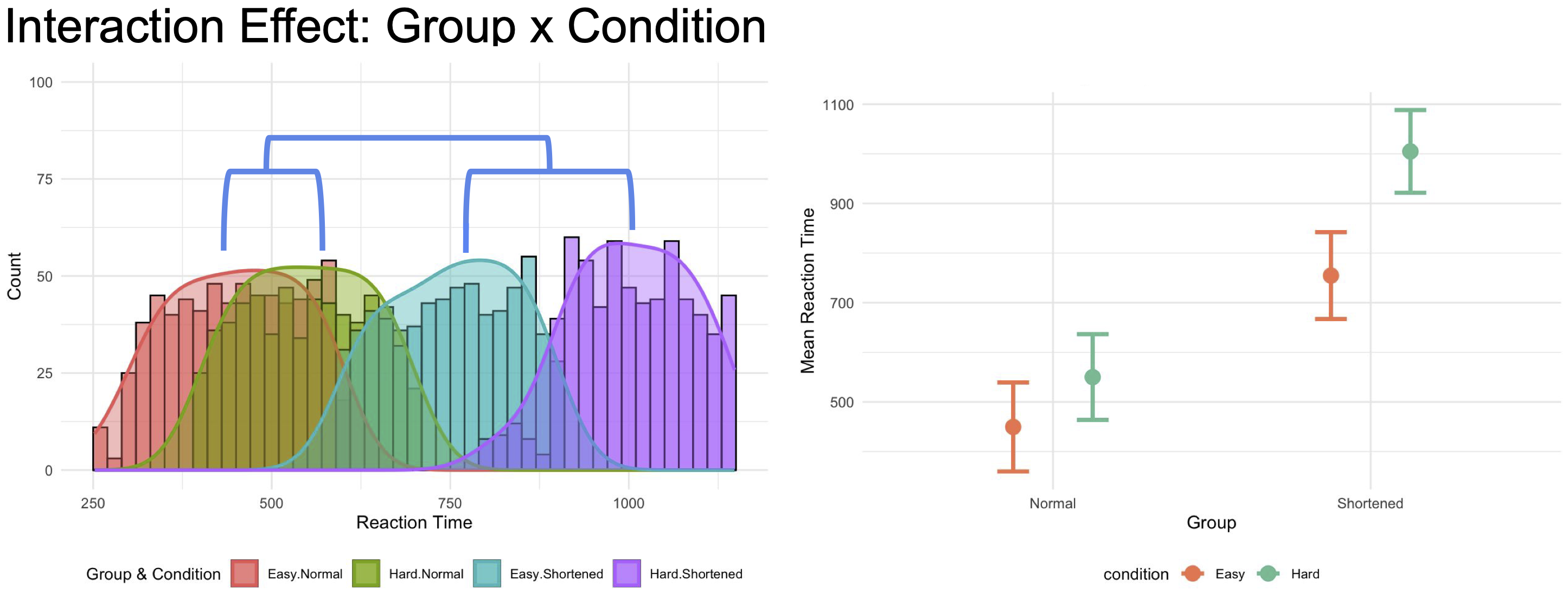
In other words, the hard version of the task always has longer reaction times than the easy version (main effect of task condition), and sleep-deprived participants always have longer reaction times than participants who got normal sleep (main effect of sleep group), but the easy vs. hard difference is exaggerated following a shortened night of sleep vs. a normal night of sleep (interaction of sleep group and task condition).